
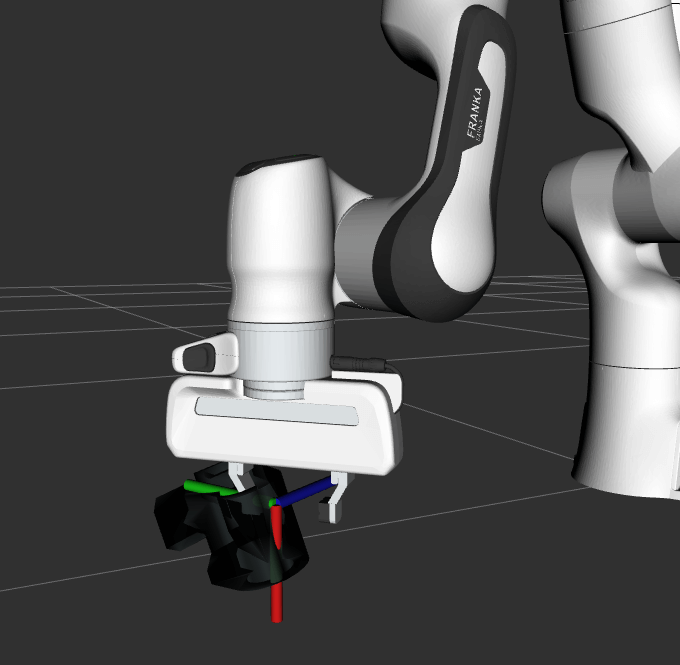
Grasping using Deep Learning
MoveIt now supports robust grasp pose generation using deep learning. Pick and place robots equipped with a depth camera and either a parallel jaw or suction gripper can increase productivity when paired with deep learning. The MoveIt Task Constructor provides an interface for any grasp pose generation algorithm making MoveIt’s pick and place capabilities more flexible and powerful.
Currently, the Grasp Pose Detection (GPD) library and Dex-Net are being used to detect 6-DOF grasp poses given 3D sensor data. GPD is capable of generating grasp poses for parallel jaw grippers and Dex-Net works with both parallel jaw and suction grippers. These neural networks are trained on datasets containing millions of images allowing them to pick novel objects from cluttered scenes.
The depth camera can either be mounted to a robot link, or be stationary in the environment. If the camera is mounted on the robot or multiple cameras are used, it is possible use multiple viewpoints to reconstruct a 3D point cloud or collect depth images. This technique allows sampling grasp candidates from views that would otherwise be occluded.
The UR5 below uses a grasp pose generated by GPD to pick up a box. The point cloud was acquired by the RealSense camera to the left of the robot.

The animation below shows the capabilities of deep learning for grasp pose generation. Dex-Net achieves greater performance in terms of successfully grasping objects, reliability, and computational speed when compared to GPD.
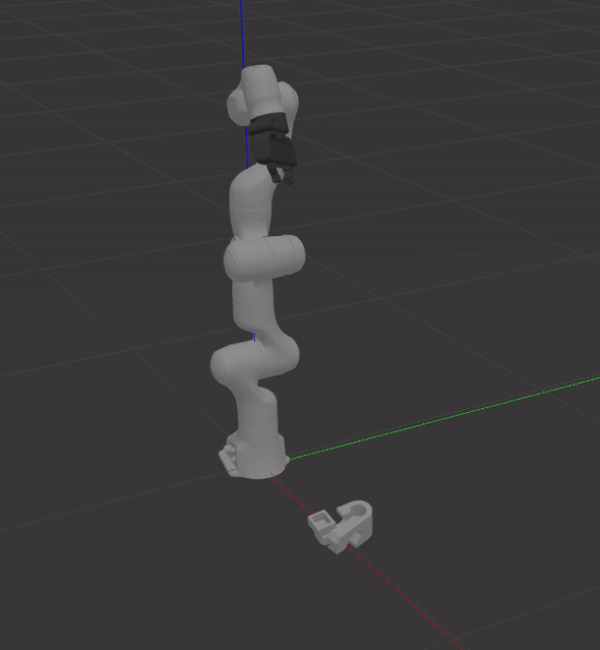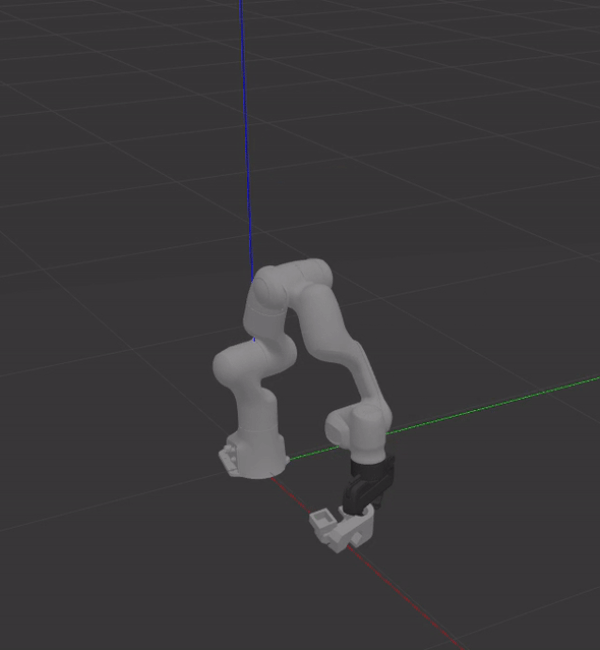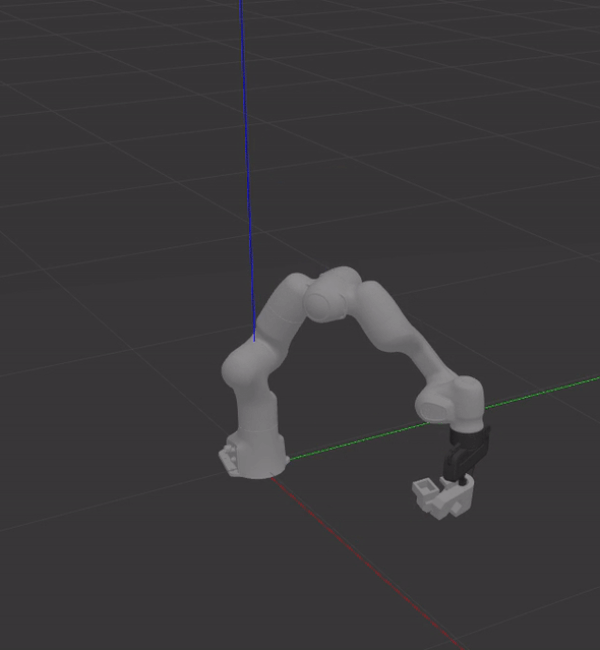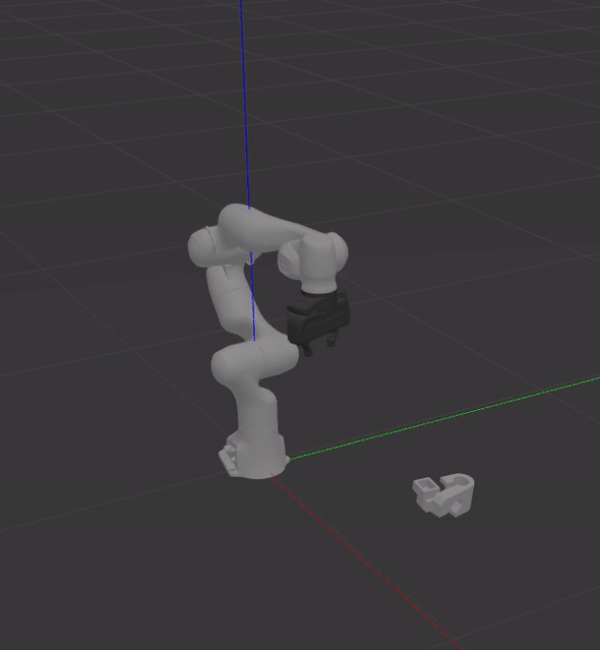 |
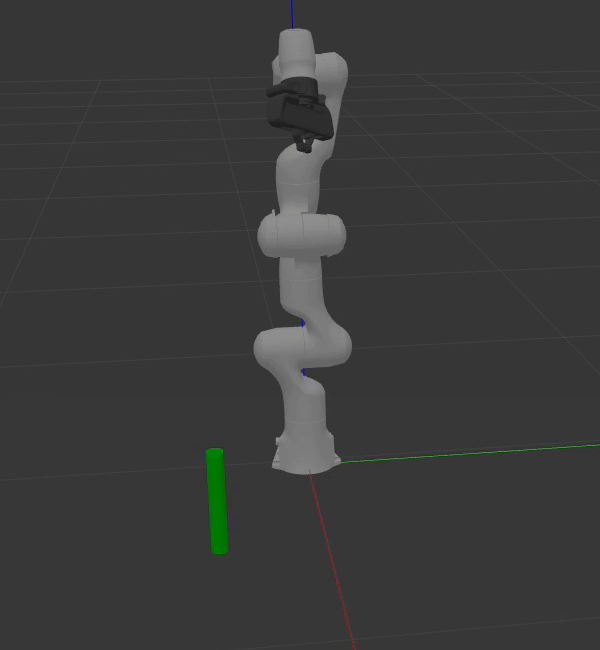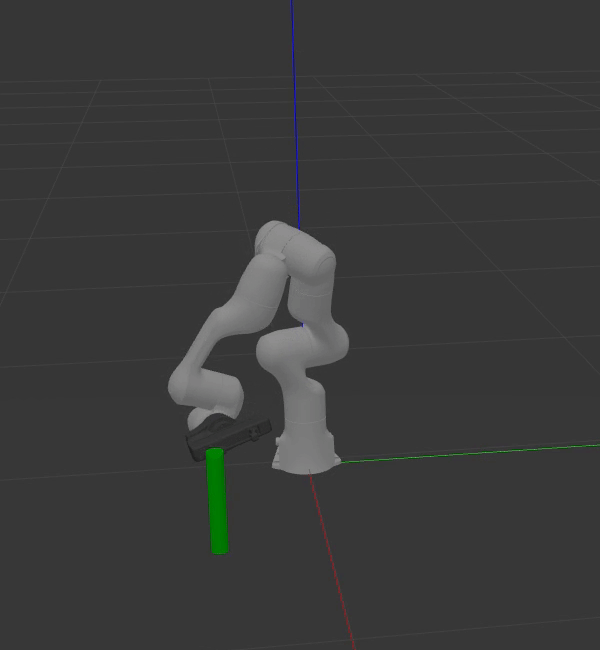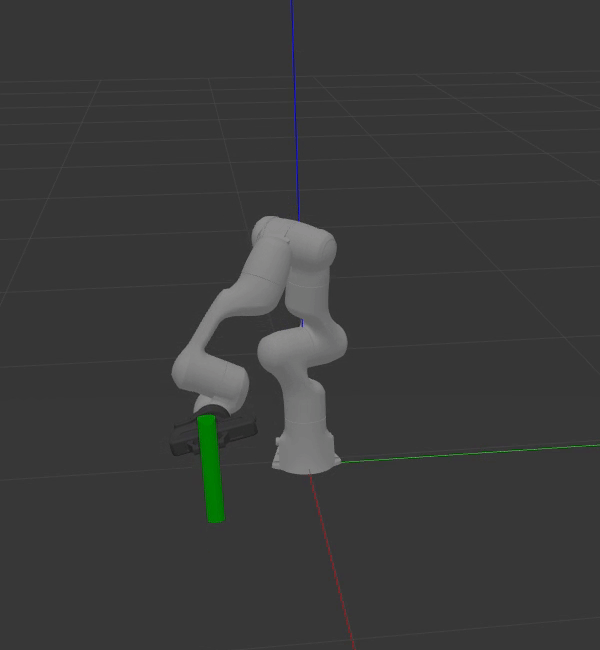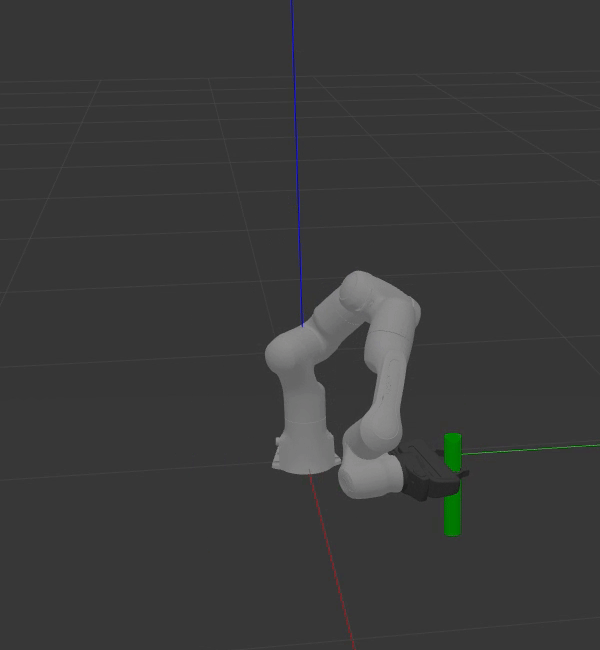 |
To learn more about how to use GPD and Dex-Net within MoveIt see the Deep Grasp Tutorial and the Deep Grasp Demo. The demo contains detailed instructions for acquiring data by simulating depth sensors and executing motion plans in Gazebo.